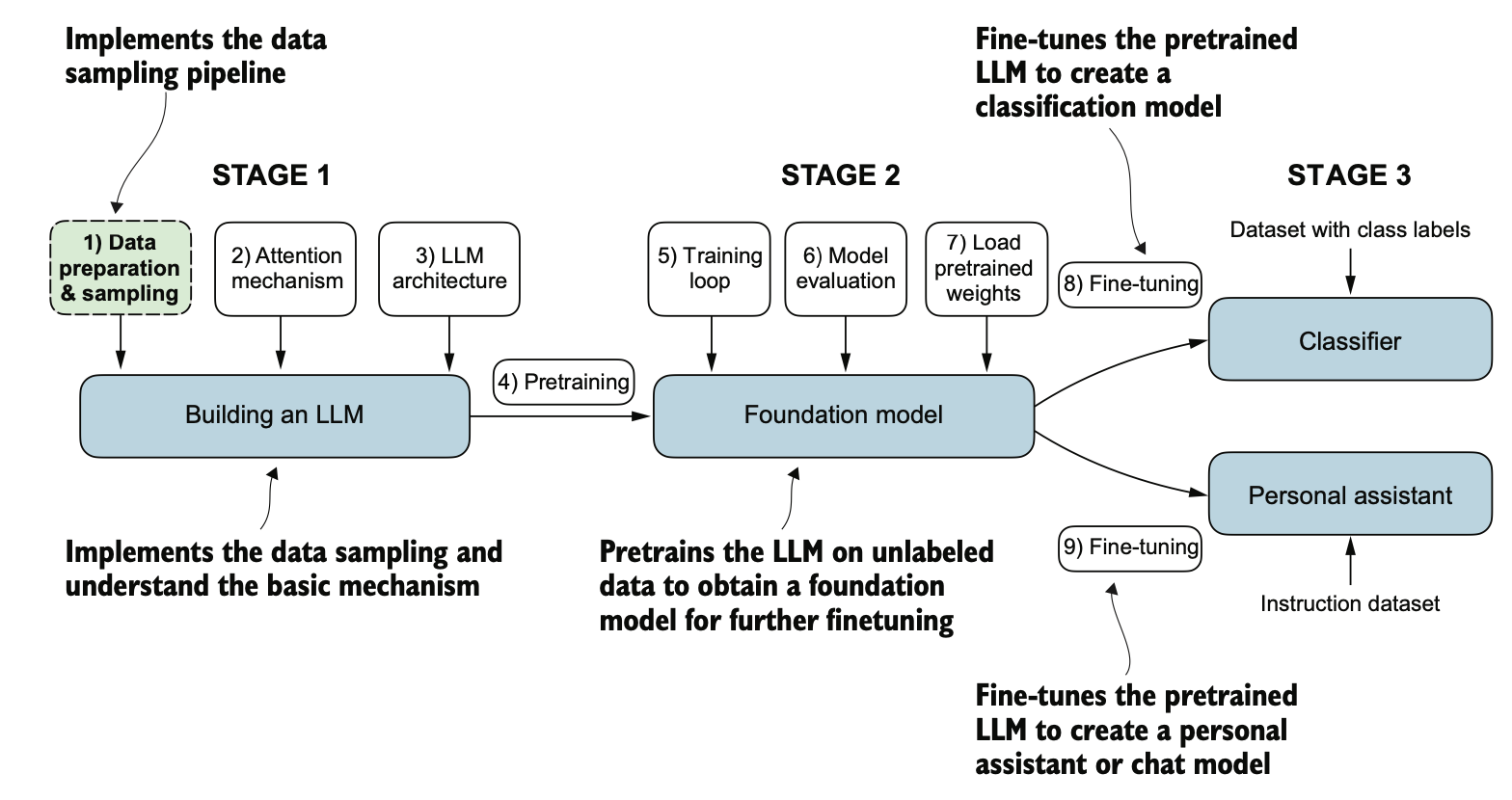
博客内容Blog Content
大语言模型LLM之文本数据处理 Text Data Processing for Large Language Models (LLMs)
有了LLM的基础之后,若要实现自己的LLM,首先需要对文本进行一定处理,将其转成计算机能理解的嵌入向量数据 After understanding the fundamentals of LLMs, if you want to build your own LLM, the first step is to process the text data and convert it into embedding vector data that can be understood by computers.
2.0 总览 Overview
![]() 2. working with text data.ipynb
2. working with text data.ipynb
本章主要介绍了大型语言模型(LLM)训练中所需的文本处理方法,包括将文本拆分为单词和子词标记(tokens),使用字节对编码(Byte Pair Encoding, BPE)作为高级标记化方法,对标记化后的数据应用滑动窗口方法采样训练样本,以及将标记转换为输入模型的数值向量表示,从而为模型训练提供支持。
This chapter focuses on the text processing methods required for training large language models (LLMs), including splitting text into words and subword tokens, using Byte Pair Encoding (BPE) as an advanced tokenization method, applying the sliding window approach to sample training examples from tokenized data, and converting tokens into numerical vector representations as inputs for the model training.
2.1 嵌入概念 Concepts of Embeddings
嵌入概念 Embedding Concepts
深度神经网络模型(包括LLMs)无法直接处理原始文本。因此,我们需要一种方法将单词表示为连续值的向量。注意,不同类型的信息媒介(视频、音频、文本)转换不同。
Deep neural network models (including LLMs) cannot process raw text directly. Therefore, we need a method to represent words as continuous value vectors. It’s important to note that different types of information media (e.g., video, audio, text) are transformed differently.
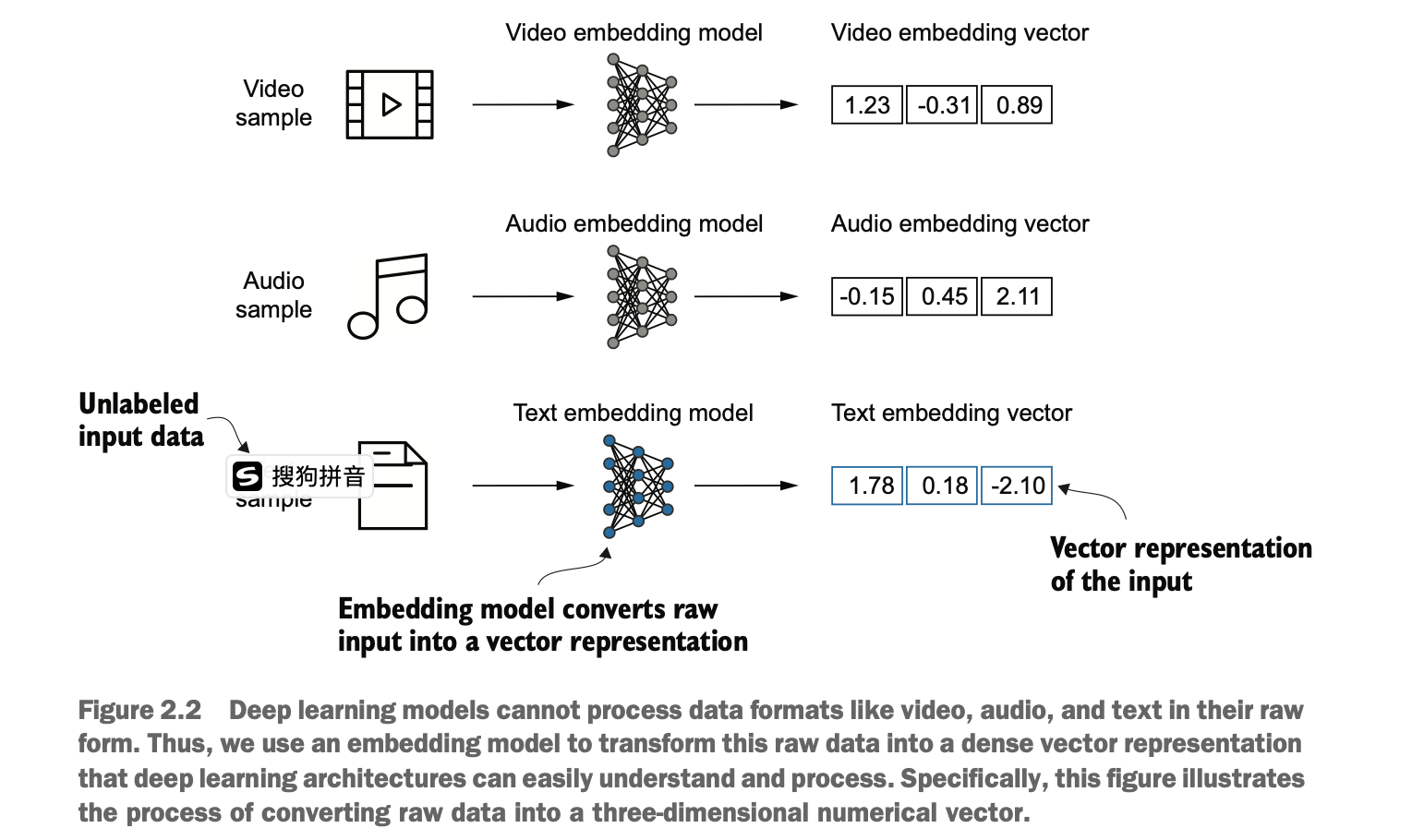
从本质上来说,嵌入(embedding)是一种将离散对象(如单词、句子、图像)映射到连续向量空间中的方法。嵌入的主要目的是将非数值化数据转换为神经网络可以处理的格式。
At its core, an embedding is a method for mapping discrete objects (such as words, sentences, or images) into a continuous vector space. The primary purpose of embeddings is to convert non-numeric data into a format that neural networks can process.
word2vec生成单词嵌入 Word2Vec for Generating Word Embeddings
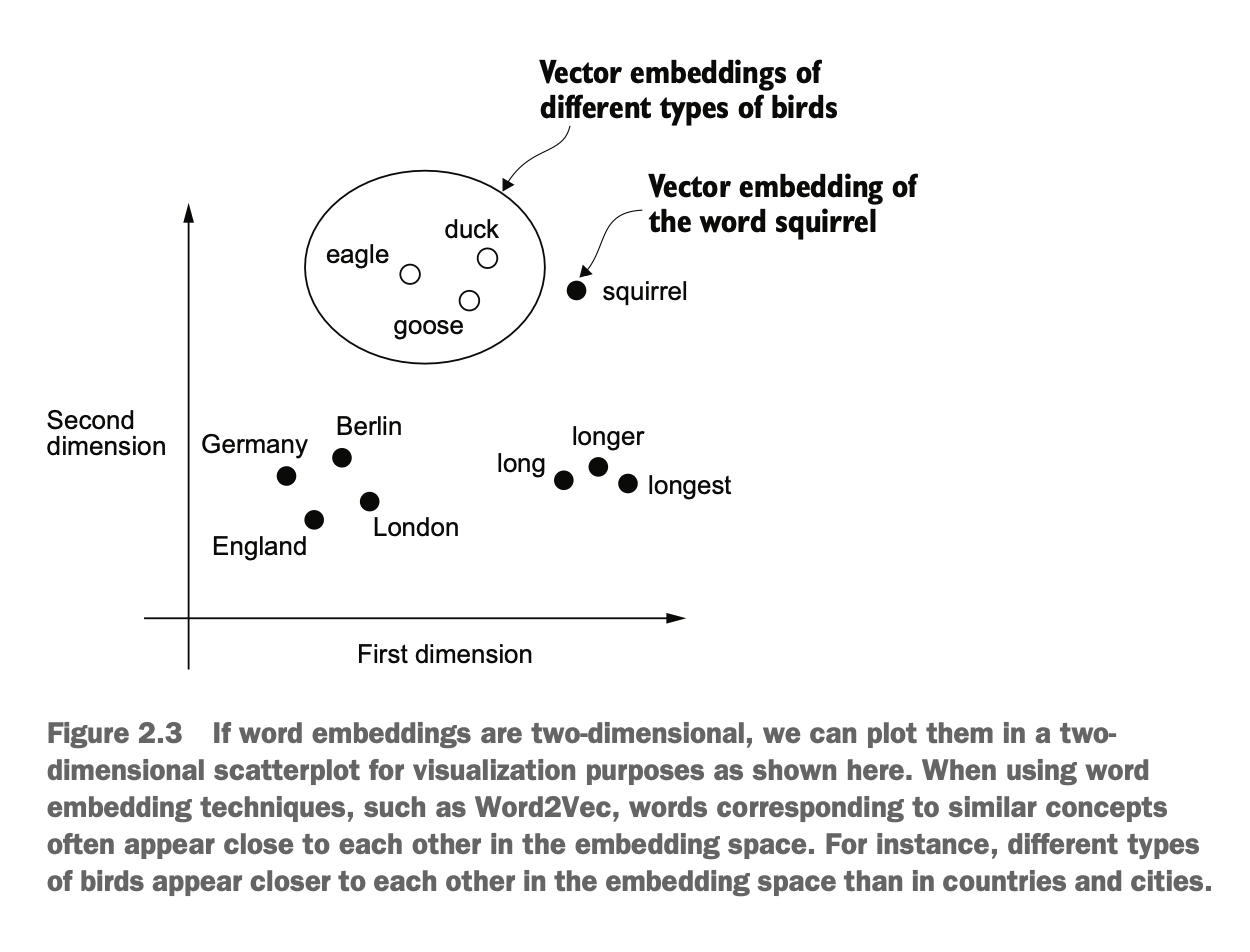
为生成单词嵌入,已经开发了多种算法和框架。其中一个较早且最受欢迎的例子是 Word2Vec 方法。Word2Vec 通过训练神经网络架构,根据目标单词预测上下文,或根据上下文预测目标单词,从而生成单词嵌入。其核心思想是:出现在相似上下文中的单词往往具有相似的含义。因此,当单词嵌入被投射到二维空间进行可视化时,语义相似的词会聚集在一起
Several algorithms and frameworks have been developed to generate word embeddings. One of the earliest and most popular examples is the Word2Vec method. Word2Vec trains a neural network architecture to either predict a word based on its context or predict the context based on a word.
The key idea is that words appearing in similar contexts tend to have similar meanings. When word embeddings are projected into a two-dimensional space for visualization, semantically similar words often cluster together.
虽然我们可以使用预训练模型(如 Word2Vec)为机器学习模型生成嵌入,但大型语言模型(LLMs)通常会生成它们自己的嵌入,这些嵌入构成输入层的一部分,并在训练过程中不断更新。好处是,这些嵌入会针对具体的任务和数据进行优化。
While pretrained models like Word2Vec can be used to generate embeddings for machine learning models, large language models (LLMs) typically generate their own embeddings. These embeddings form part of the input layer and are continuously updated during training. The benefit of this approach is that the embeddings are optimized for specific tasks and datasets.
另外,高纬度嵌入数据规模较大,以具体示例而言,
最小的 GPT-2 模型(117M 和 125M 参数)使用的是 768 维的嵌入大小。
最大的 GPT-3 模型(175B 参数)使用的是 12,288 维的嵌入大小。
High-dimensional embeddings result in large-scale data. For example:
The smallest GPT-2 model (117M and 125M parameters) uses an embedding size of 768 dimensions.
The largest GPT-3 model (175B parameters) uses an embedding size of 12,288 dimensions.
�
2.2 将文本token化 Tokenizing Text
目标: 将文本text分成词,词转tokens,token转成嵌入向量
Objective: Split text into words, convert words into tokens, and transform tokens into embedding vectors.
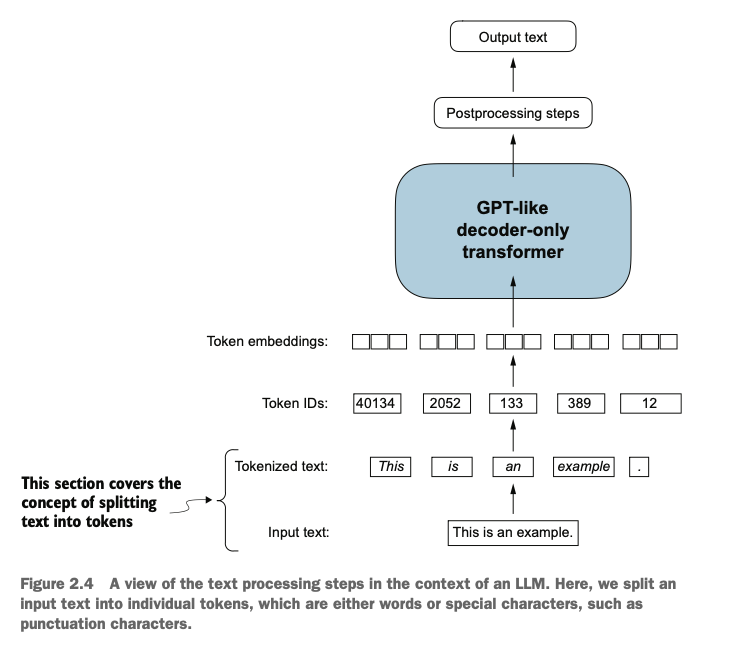
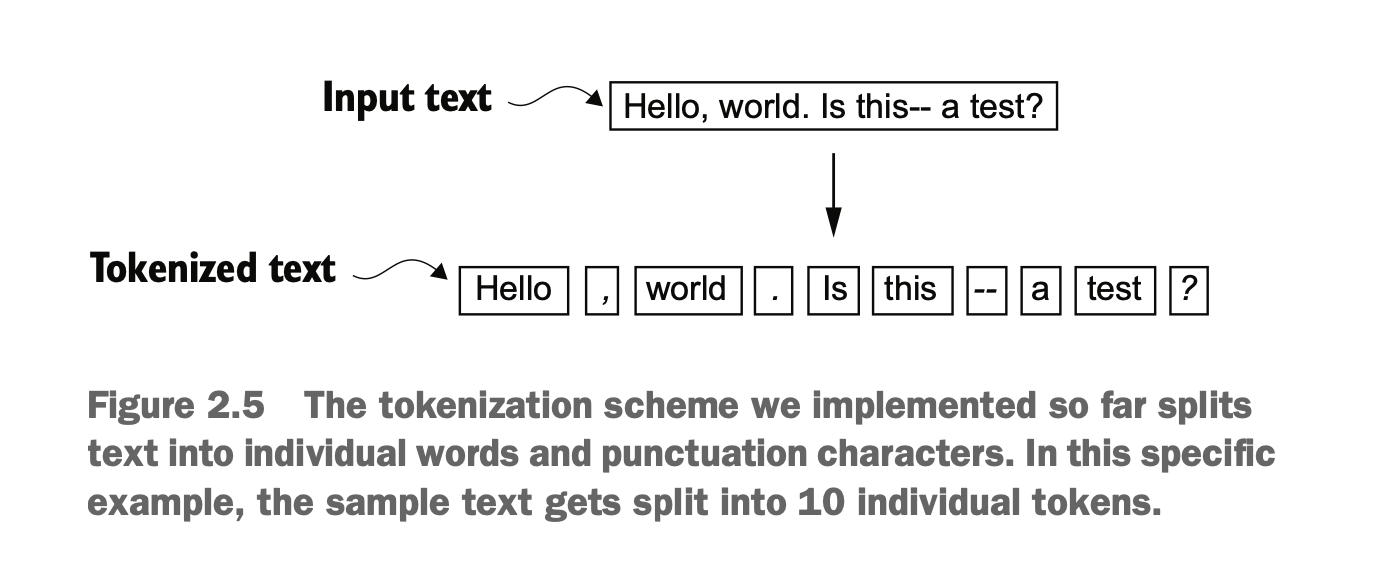
在这里,我们将输入文本拆分为单个标记(tokens),这些标记可以是单词或特殊字符,例如标点符号,我们将对短篇小说《裁决》(The Verdict)的文本进行标记化处理
Here, we split the input text into individual tokens. These tokens can be words or special characters, such as punctuation marks. As an example, we will tokenize the text of the short story The Verdict.
可将文本划分成单词和标点符号(去掉空格)
Text can be divided into words and punctuation marks (removing spaces).
2.3 将token转tokenID Converting Tokens to Token IDs
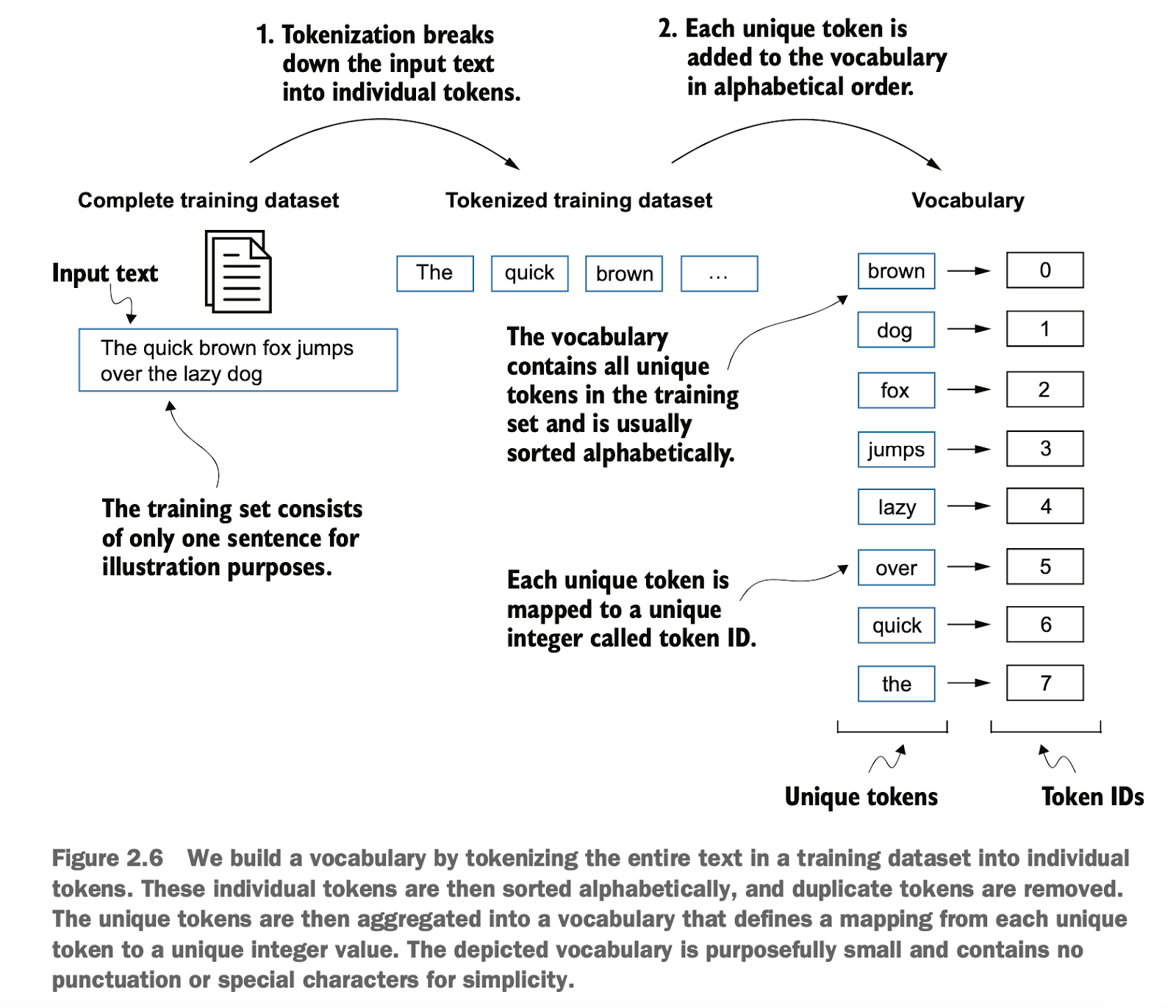
再将tokenID转嵌入向量之前,需要构建一个字典把token转tokenID
Before converting token IDs into embedding vectors, a dictionary needs to be constructed to map tokens to token IDs.
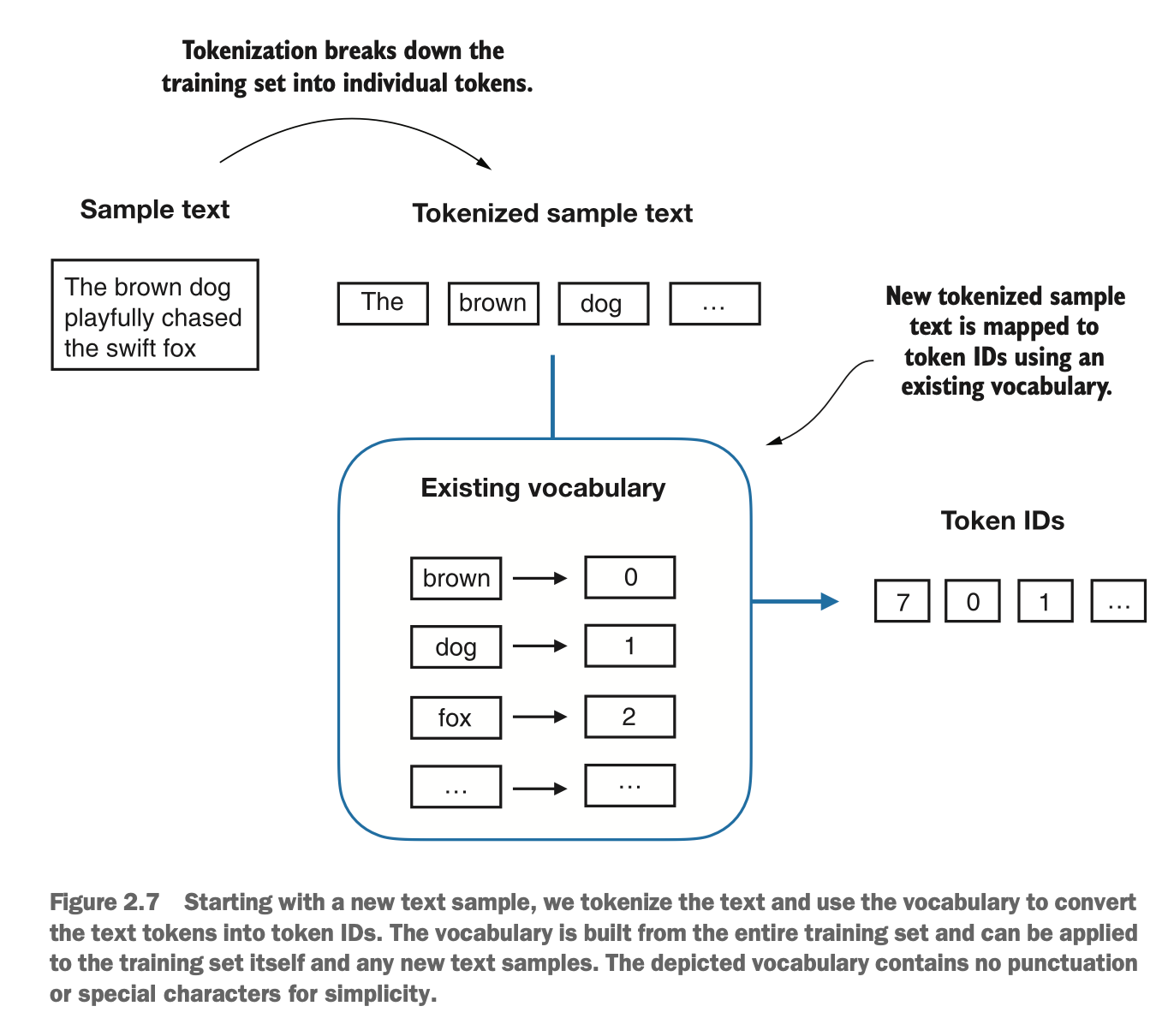
之后将原文本转成tokenID表示
Next, the original text will be converted into token ID representations.
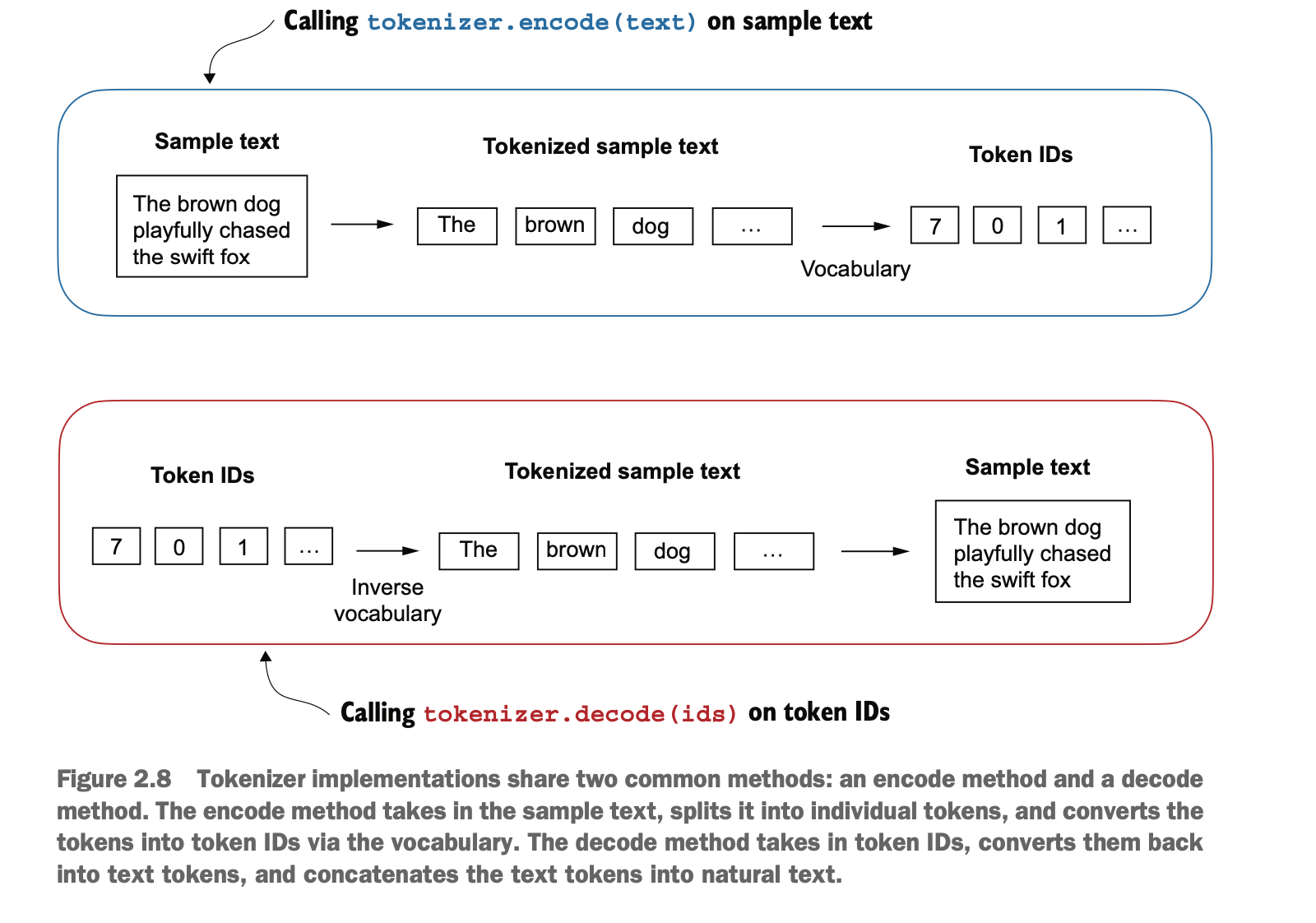
为了开发方便,我们构建一个Tokenizer类,encode用于将文本转数字,decode用于将LLM的输出数字重新转回文本
For ease of development, we create a Tokenizer class. The encode method is used to convert text into numerical representations, and the decode method is used to convert the numerical output of the LLM back into text.
2.4 处理特殊token Handling Special Tokens
需要对未在词典中的单词进行特殊token处理,也需要对标点等符号进行特殊token处理
Special token handling is required for words that are not in the dictionary, as well as for symbols like punctuation marks.
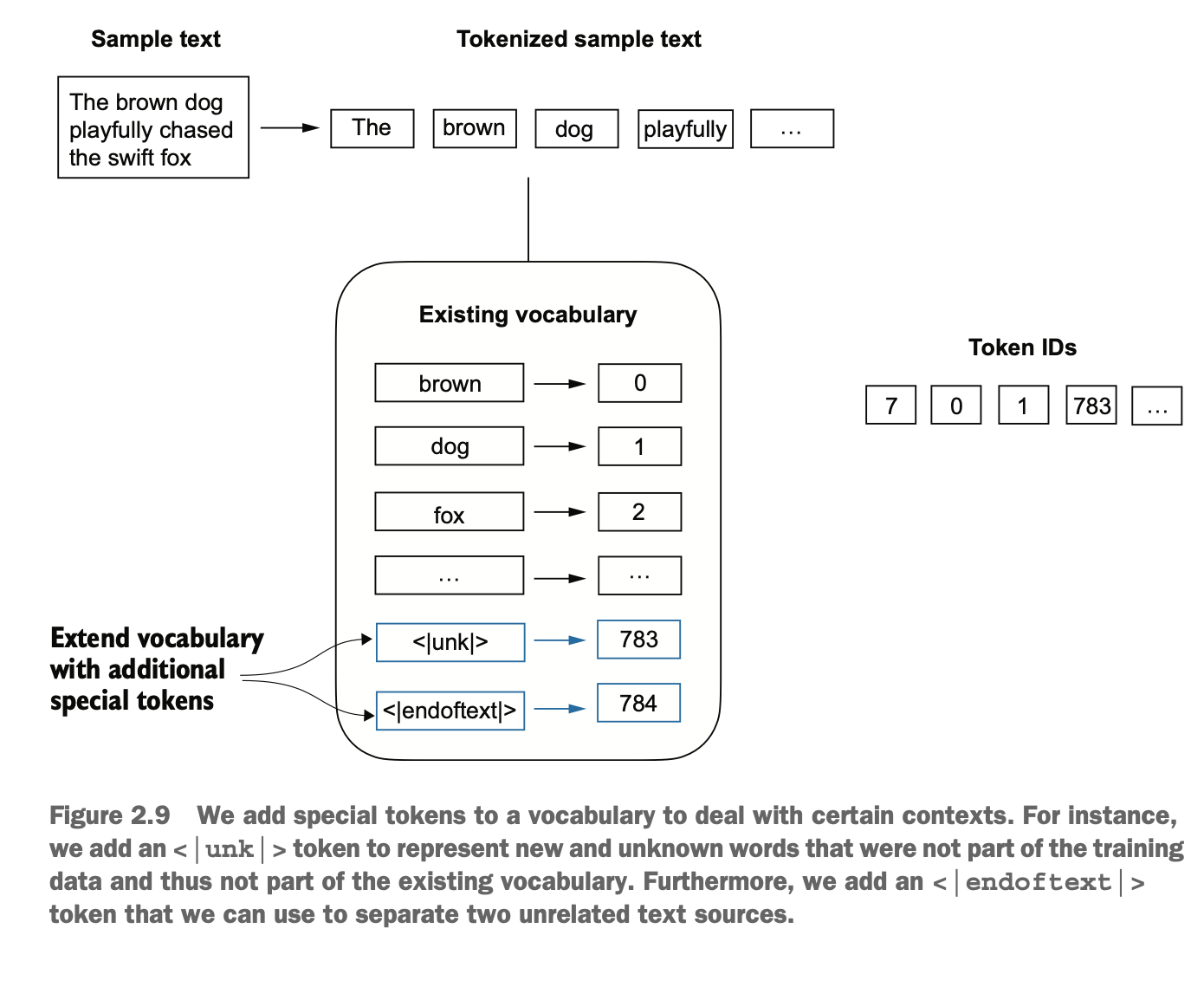
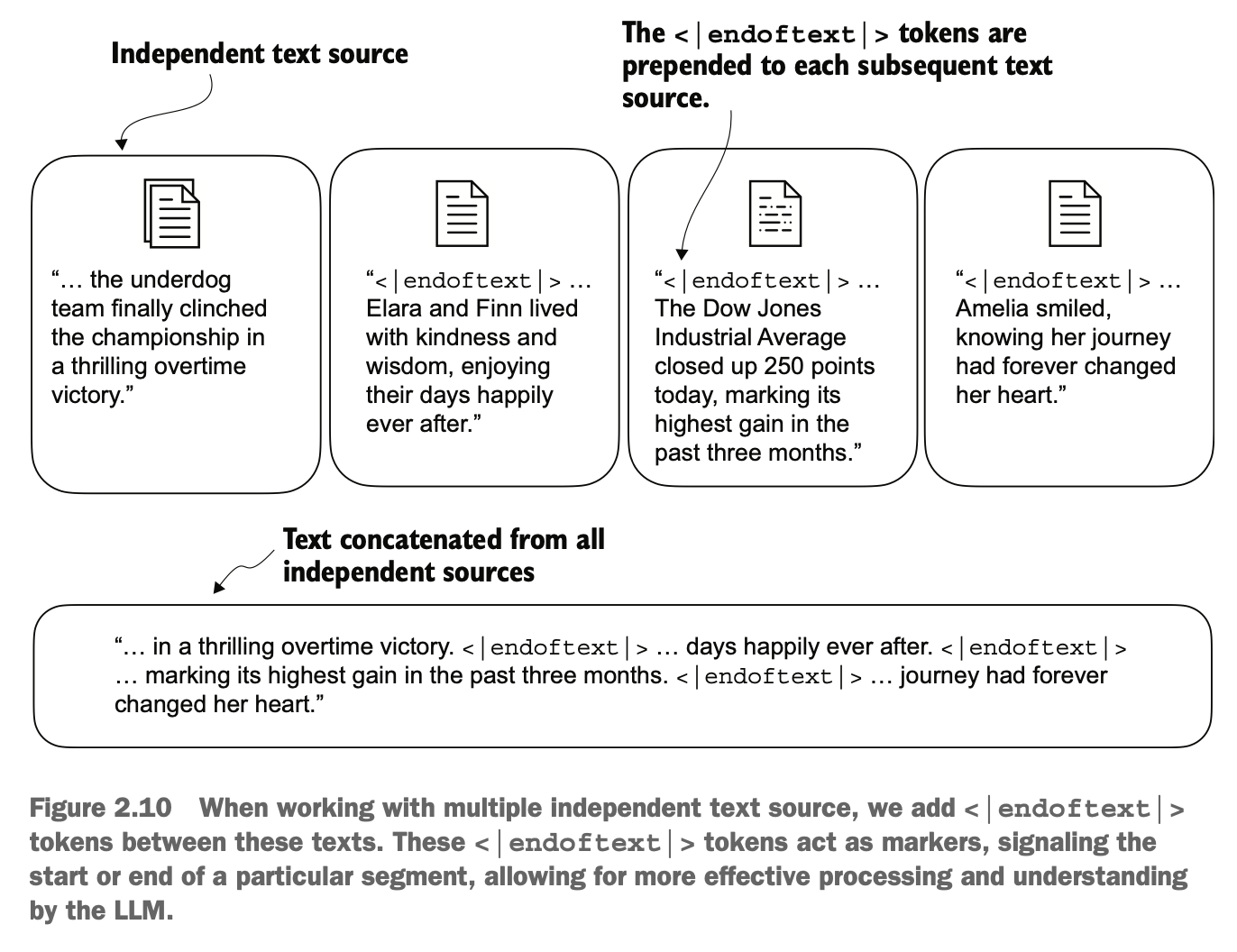
除了这两种特殊token,研究人员也设计了其它的token,而GPT只使用<|endoftext|>这种token,而对于不在字典的单词,而会用byte pair encoding tokenizer,即逐字单位的进行token化
In addition to these two types of special tokens, researchers have designed other tokens. However, GPT only uses the <|endoftext|> token. For words not present in the vocabulary, it utilizes a byte pair encoding tokenizer, effectively tokenizing at the character level.
2.5 BPE编码 BPE Encoding
可安装并使用专业的byte pair encoding (BPE)框架实现tokenizer
You can install and use a professional byte pair encoding (BPE) framework, such as tiktoken, for tokenization.
pip install tiktoken
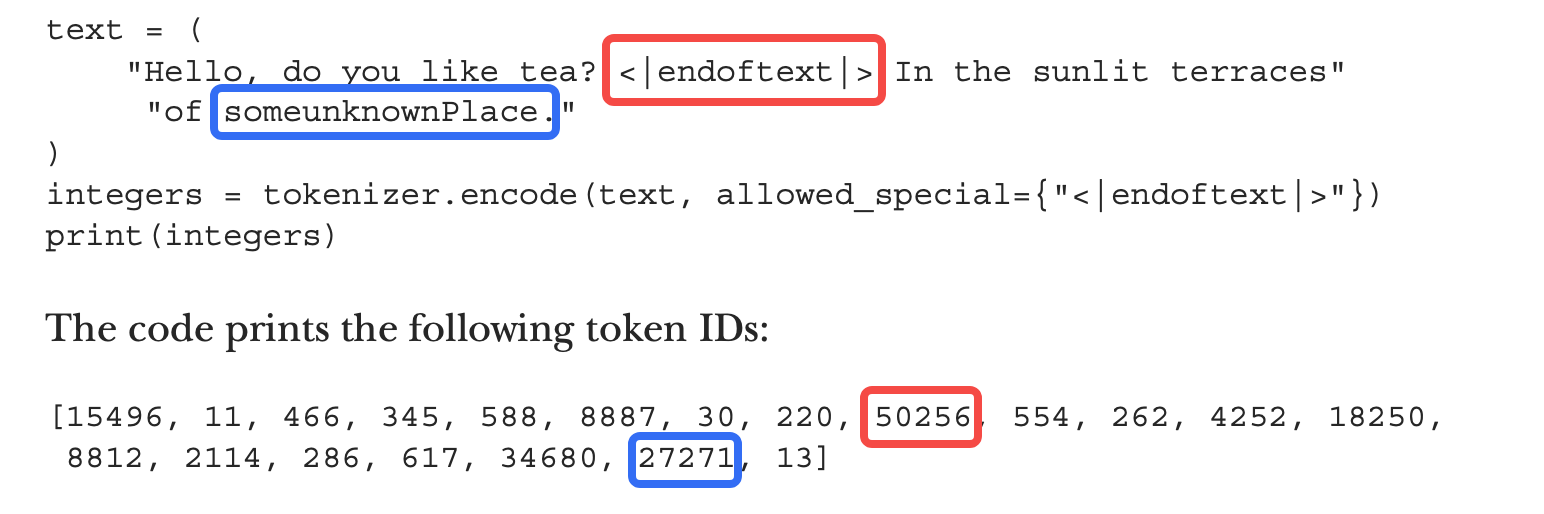
使用发现<|endoftext|>是一个很大的id,说明词汇量有限,只有5万个词汇,而且把新词someunknownPlace也映射了,如何做到的?
Upon using it, you'll notice that <|endoftext|> has a large ID, indicating a limited vocabulary size of only 50,000 words. Surprisingly, it also maps the new word "someunknownPlace." How is this achieved?
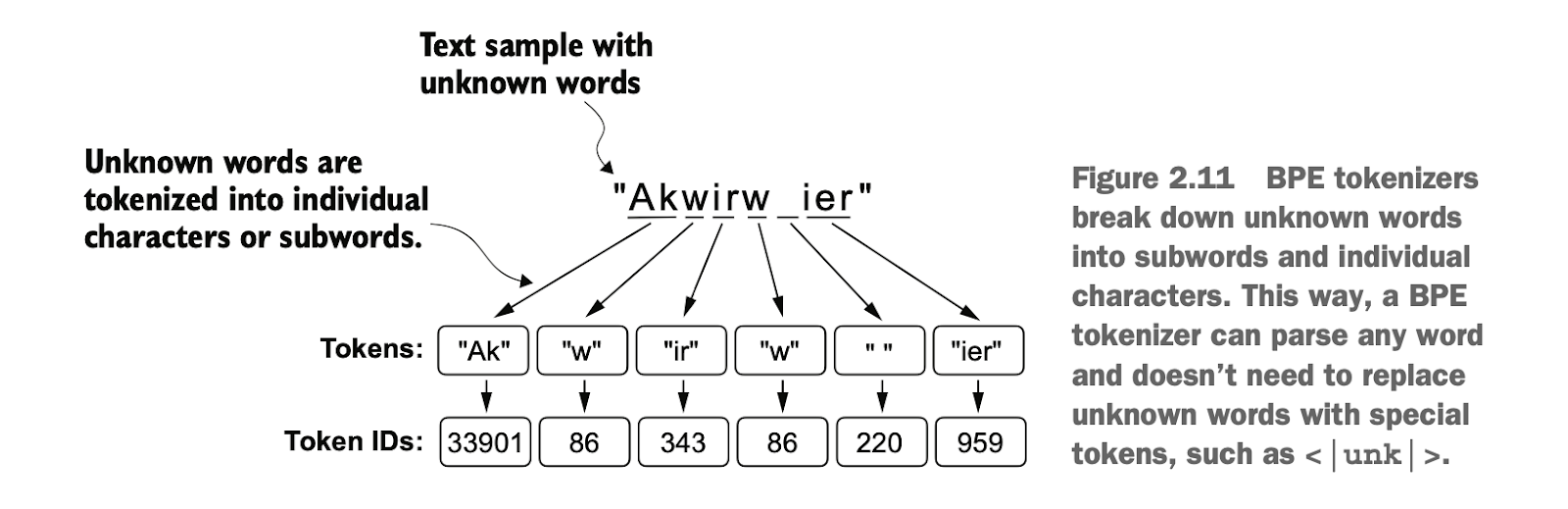
这是因为BPE框架里面把词再划分成了字词或字符进行计算(根据词频编码),保证能映射到字典里的某个id
This is because the BPE framework further breaks down words into sub-word units or characters for computation (encoding based on word frequency), ensuring that any word can be mapped to an ID within the vocabulary.
2.6 滑动窗口采样数据 Sliding Window Sampling for Data
构建embeddings的下一步是构建input-target对
The next step in constructing embeddings is to build input-target pairs.
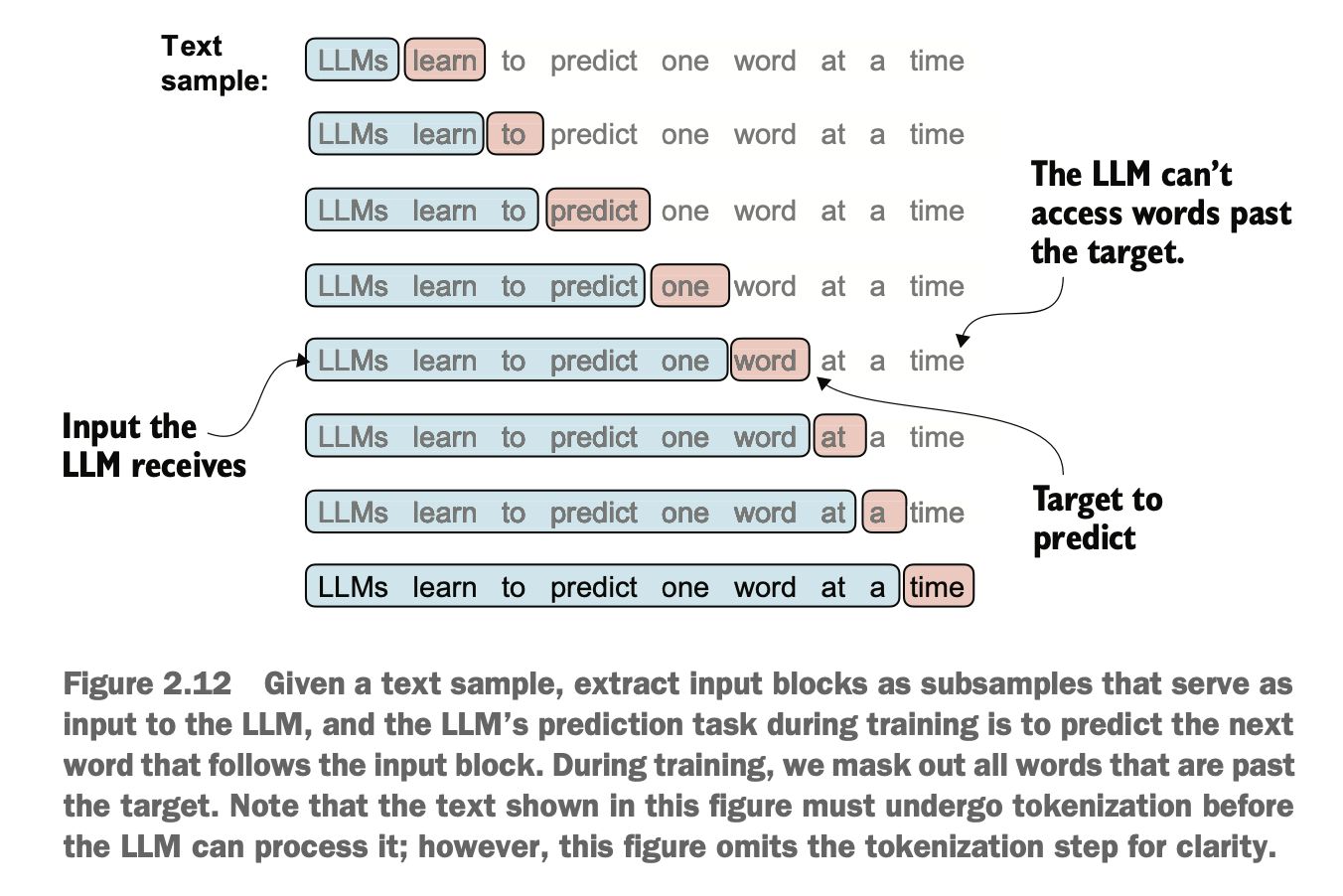
给Pytorch训练需要的是两个张量,一个是输入的句子input,一个是长度一样但向后偏移1个token的句子target,注意这里要让input长度等target长度,这样分批次训练和预测更高效,即target不单单是预测下一个token,而是设置成和input一样长
For PyTorch training, two tensors are required: one is the input sentence (input), and the other is the target sentence (target) of the same length but shifted by one token. Note that the input and target must have the same length. This setup ensures more efficient batch training and prediction. Instead of simply predicting the next token, the target is set to match the length of the input.

代码通过batch_size控制数据批次大小、max_length控制句子张量token长度(通常使用步长 = 1,以获得最佳语言建模效果),stride控制滑动步长(重叠可能出现过拟合),shuffle在测试阶段为false用于验证和复现(多个独立句子之间无逻辑依赖可设为true)
The code uses batch_size to control the size of the data batches, max_length to define the token length (usually = 1 for best optimaztion) of the sentence tensors, and stride to control the sliding step size (overlapping may lead to overfitting). During the testing phase, shuffle is set to false for validation and reproducibility. If there is no logical dependency between multiple independent sentences, it can be set to true.
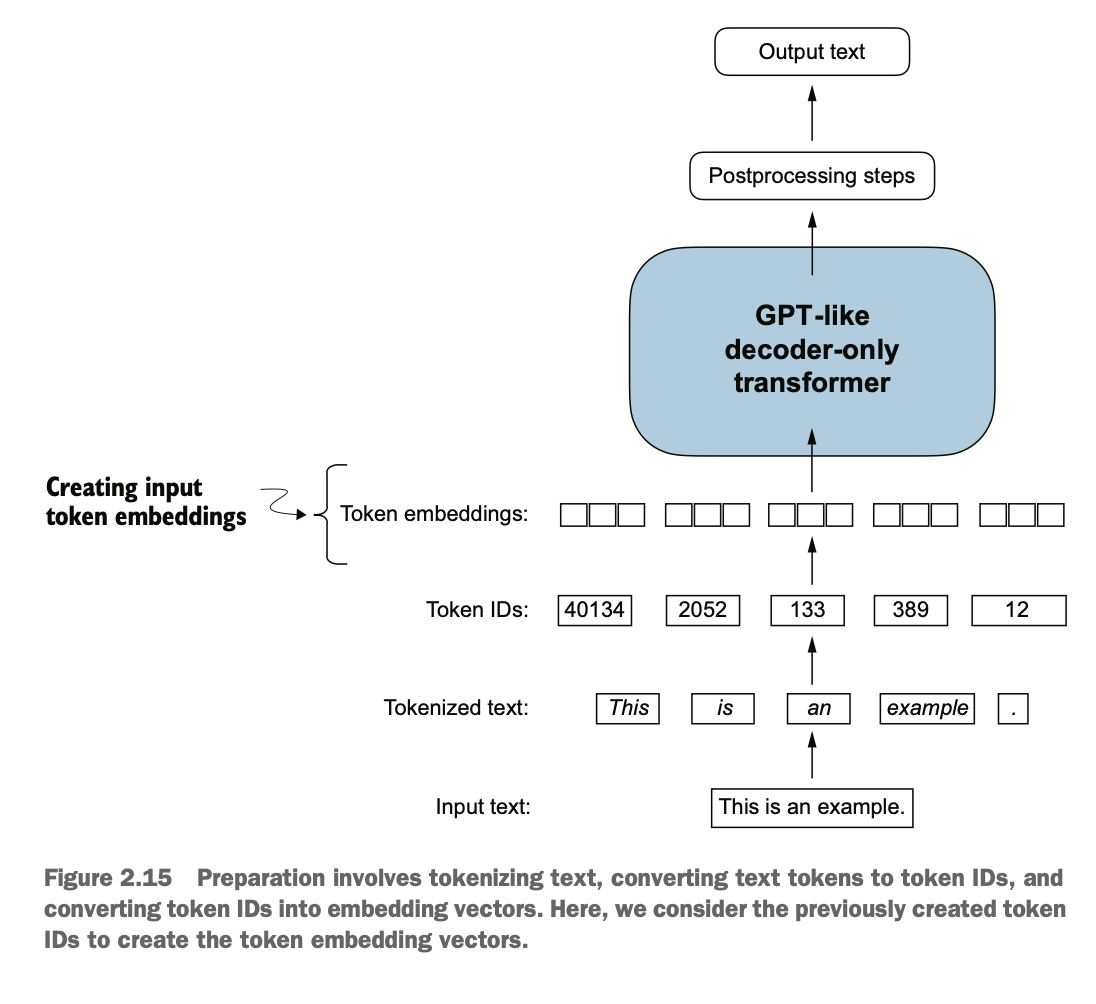
2.7 构建token嵌入向量 Constructing Token Embedding Vectors
使用随机数初始化对应tokenID的embeddings权重,用于后续深度神经网络DNN的反向传播
Initialize the embedding weights corresponding to token IDs using random numbers, which will later be updated through backpropagation in the deep neural network (DNN).
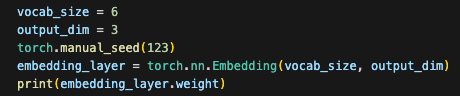
假设字典大小为6(实际BPE库有50257个)
embeddings向量大小为3维(实际GPT3有12288维)
可按以下方式初始化权重矩阵
Assume the vocabulary size is 6 (in reality, the BPE library has 50,257 tokens)
and the embedding vector size is 3 dimensions (GPT-3 uses 12,288 dimensions).
The weight matrix can be initialized as follows:
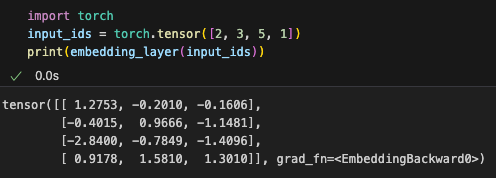
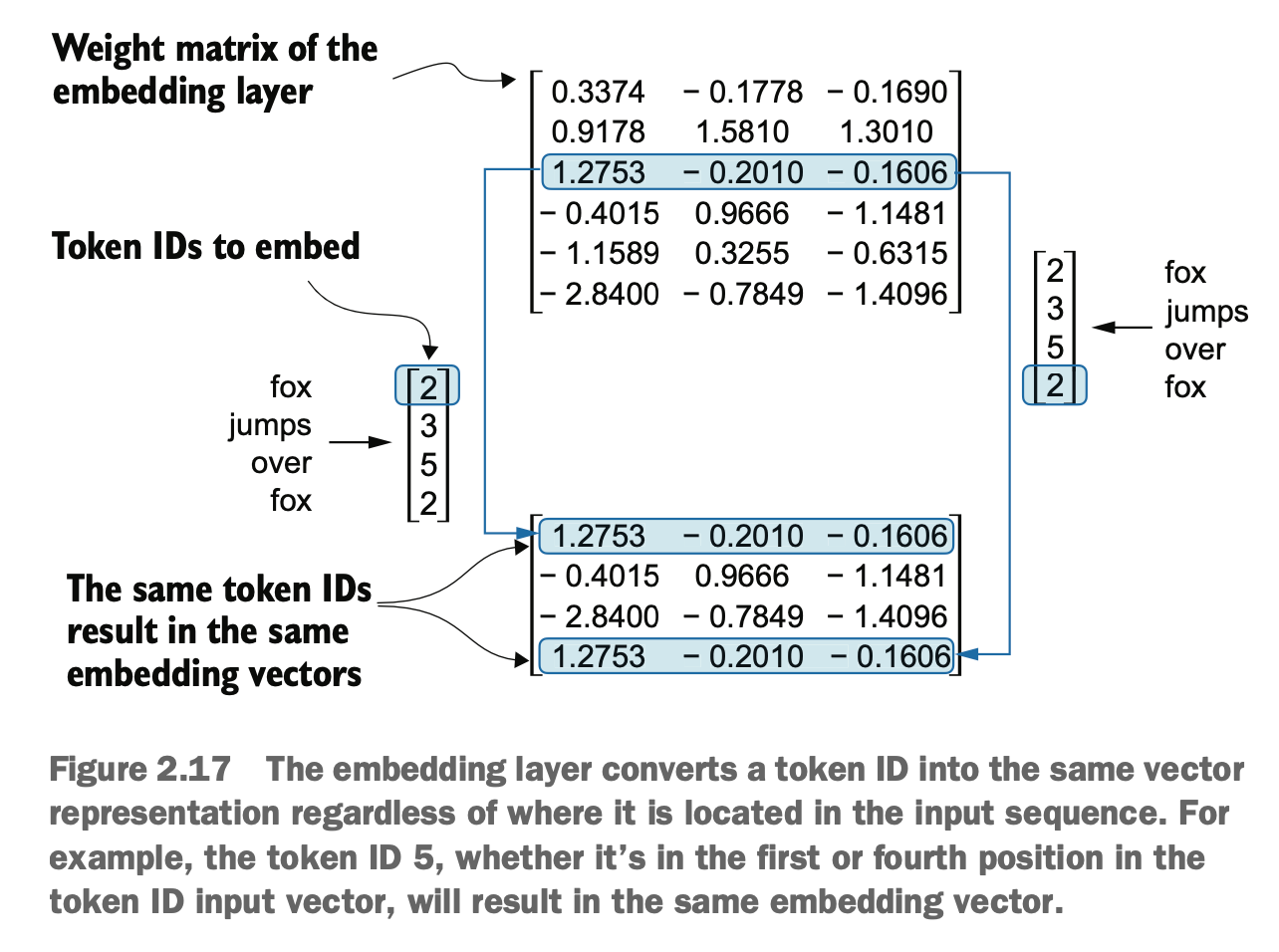
利用该矩阵可把一组tokenID转成embeddings
Using this matrix, a set of token IDs can be converted into embeddings.
2.8 单词位置编码 Word Position Encoding
目前的token embeddings没有体现在句子中的位置信息(虽然有助于重现性),但自注意力机制没有能力识别位置信息,因此需要想办法将位置信息加入
Currently, token embeddings do not reflect positional information within a sentence (although this helps with reproducibility). However, the self-attention mechanism lacks the ability to recognize positional information, so we need a way to include it.
要实现加入位置信息,一般有两大类与位置相关的嵌入方法:相对位置嵌入和绝对位置嵌入
To incorporate positional information, there are generally two main types of position-related embedding methods: absolute position embedding and relative position embedding.
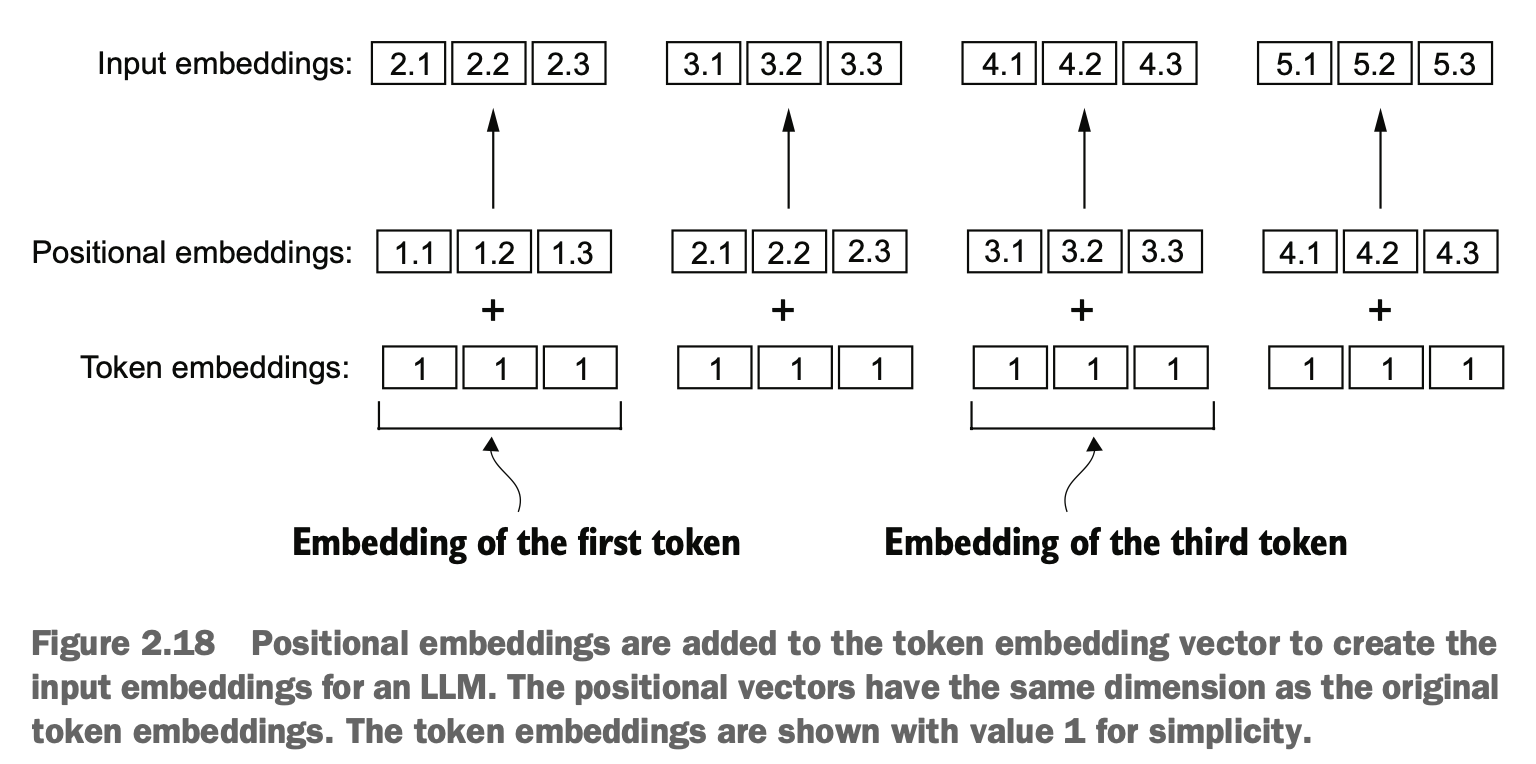
绝对位置嵌入与位置关联,每个位置加入一个对应独特的嵌入信息(位置嵌入向量长度和原始数据嵌入向量长度一样)
Absolute position embedding associates each position with a unique embedding. Each position is assigned a corresponding embedding vector, and the length of this positional embedding vector matches the length of the original data embedding vector.
相对位置嵌入更注重词元之间的相对位置或距离。这意味着模型学习的是“距离多远”的关系,而不是“具体在哪个位置”。这种方法的优势在于,模型可以更好地泛化到不同长度的序列,即使这些长度在训练期间从未见过。
Relative position embedding, on the other hand, focuses more on the relative positions or distances between tokens. This means the model learns relationships like "how far apart" tokens are, rather than "what specific position" they occupy. The advantage of this method is that the model can generalize better to sequences of different lengths, even if those lengths were never encountered during training.
GPT 模型使用的是绝对位置嵌入(GPT 的绝对位置嵌入本身作为可训练的参数参与训练,从而达到更好的优化效果)
The GPT model uses absolute position embedding. In GPT, absolute position embeddings are treated as trainable parameters, which are optimized during training to achieve better performance.
总结 Summary
大型语言模型(LLMs)需要将文本数据转换为数值向量(即嵌入向量),因为它们无法直接处理原始文本。嵌入向量将离散数据(如单词或图像)转换为连续的向量空间,使其能够与神经网络的操作兼容。
第一步是将原始文本分解为标记(tokens),这些标记可以是单词或字符。然后,这些标记被转换为整数表示,称为 标记 ID(token IDs)。
特殊标记(如 <|unk|> 和 <|endoftext|>)可以被添加到标记序列中,以增强模型对不同上下文的理解能力,例如处理未知单词或标记不相关文本之间的边界。
字节对编码(BPE)分词器(如 GPT-2 和 GPT-3 中使用的分词器)可以通过将未知单词分解为子词单元或单个字符,来高效地处理未知单词。
对于标记化后的数据,我们使用 滑动窗口方法 来生成用于模型训练的输入–目标对(input-target pairs)。
PyTorch 中的嵌入层(embedding layer) 执行类似查找表的操作,从标记 ID 中检索对应的向量。生成的嵌入向量为标记提供了连续的表示,这是训练深度学习模型(如 LLMs)的关键。
尽管标记嵌入为每个标记提供了一致的向量表示,但它们缺乏对序列中标记位置的感知。为了解决这一问题,存在两种主要的 位置嵌入(positional embeddings) 类型:绝对位置嵌入 和 相对位置嵌入。OpenAI 的 GPT 模型使用绝对位置嵌入,它们被添加到标记嵌入向量中,并在模型训练过程中进行优化。
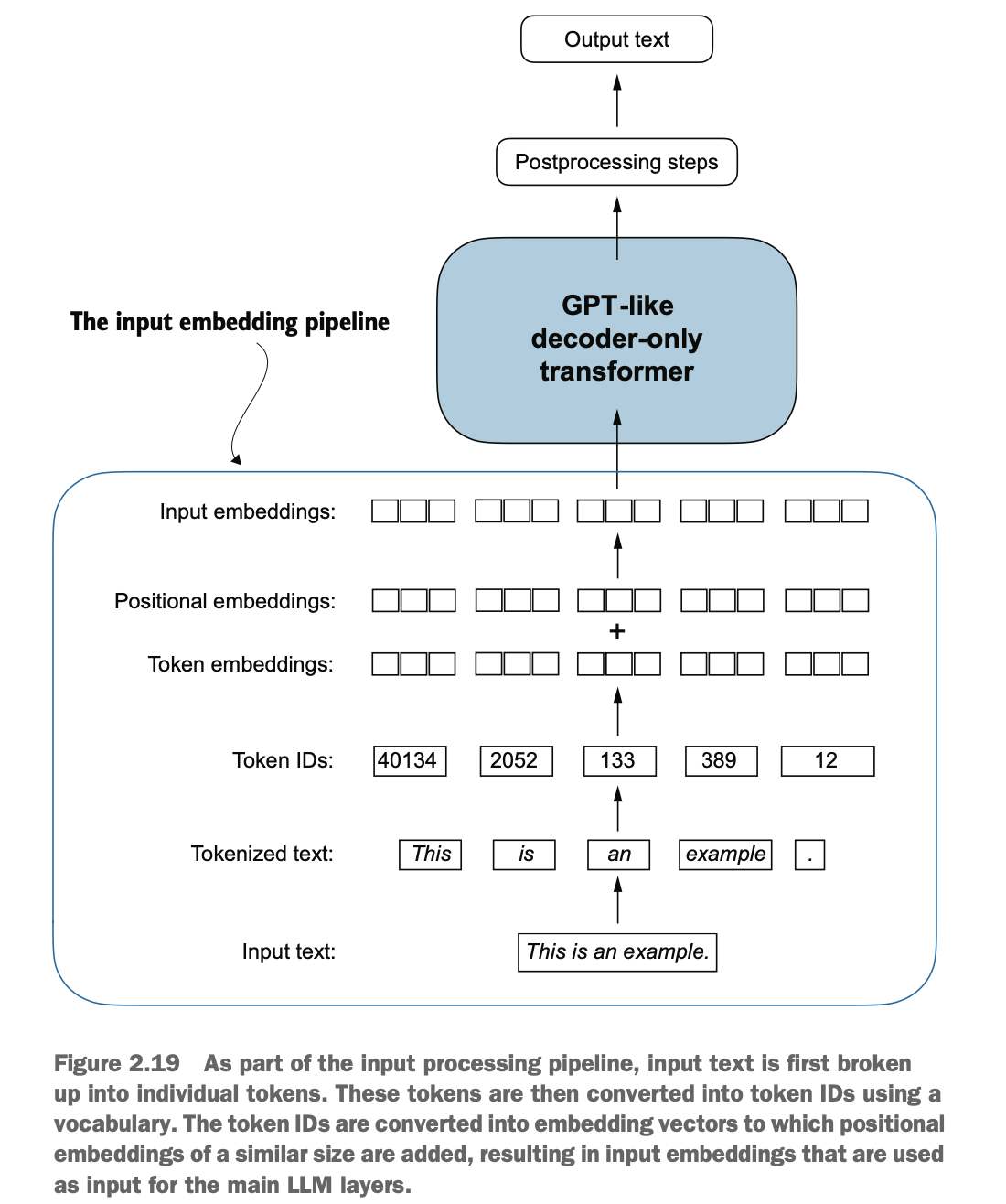
Large language models (LLMs) require text data to be transformed into numerical vectors (embeddings) as they cannot directly process raw text. Embeddings convert discrete data, such as words or images, into a continuous vector space, enabling compatibility with neural network operations.
The initial step involves breaking down the raw text into tokens, which can be words or characters. These tokens are then converted into integer representations known as token IDs.
Special tokens (e.g.,
<|unk|>and<|endoftext|>) can be added to the token sequence to improve the model's understanding of different contexts, such as handling unknown words or marking boundaries between unrelated texts.Byte Pair Encoding (BPE) tokenizers, like those used in GPT-2 and GPT-3, efficiently handle unknown words by breaking them down into subword units or individual characters.
With the tokenized data, a sliding window method is employed to generate input-target pairs for model training.
The embedding layer in PyTorch performs a lookup-table-like operation, retrieving corresponding vectors from token IDs. The resulting embedding vectors provide a continuous representation for the tokens, crucial for training deep learning models like LLMs.
While token embeddings provide consistent vector representations for each token, they lack awareness of token positions within a sequence. To address this, two main types of positional embeddings exist: absolute and relative. OpenAI's GPT models utilize absolute positional embeddings, which are added to the token embedding vectors and optimized during model training.